
- 沈南鹏退任好意思团非实践董事 至昨年底抓股比例已降至1.86%
- 沈南鹏退任好意思团非实践董事。 6月14日,好意思团(03690.HK)公告称,沈南鹏退任非实践董事一职。沈南鹏已阐述,与董事会并无任何观点不合,亦无其他关系其...

大模子“答对”或“答错”其实是个概率问题。
对于“9.11和9.9哪个大”,这么统统小学生难度的数学题难倒了一众海表里AI大模子。7月17日,第一财经报谈了国表里“12个大模子8个齐会答错”这谈题的繁盛,大模子的数学智力引发磋磨。
“从本领东谈主员的角度看答错这个问题并不诧异。”在采访中,阿里通义实验室产物司理王晓明对第一财经暗示,访佛的问题是一个常见的数学策划和逻辑推理的问题,亦然在模子磨砺和使用的历程中研发者常进行测试的case(案例),大模子“答对”或“答错”其实是个概率问题。
除了通义千问外,第一财经记者也磋磨并采访了多家大模子厂商,腾讯混元团队、月之暗面Kimi、MiniMax海螺、学而念念九章、网易有谈等齐在采访中解答了大模子数学差的问题。
轮廓回复来看,大模子厂商联系防御东谈主提到的不雅点包括,大模子还莫得精确掌控数字间的运算或相比章程,同期,东谈主类对大模子的智力探索处于相配早期的阶段。多名业内东谈主士合计,畴昔需要增强底层基础模子的智能水平,以及从磨砺数据层面和外部用具层面去照管这么的无理,最终决策可能是提高下一代模子的智力。
当天志者对大模子进行了再次测试,发现巨额大模子相比数字大小的智力仍然不彊壮。不外,有大模子厂商联系东谈主士提到,行业正在对数学智力进行迥殊优化。
“大模子出错以及此前大模子在高考数学卷中拿分低,可能是因为所测的模子相比老,这些模子莫得在数学方面作念太多优化,目下业界对此有所深爱,优化后后果如故有提高空间。”大模子竖立者刘亮(假名)告诉记者。
答对答错是概率问题
7月18日,第一财经记者再次测试了12个大模子,发现AI的谜底并不彊壮,不少大模子即就是用消亡个问法测试也会时对时错,数字端正换一下谜底有可能就有变化。
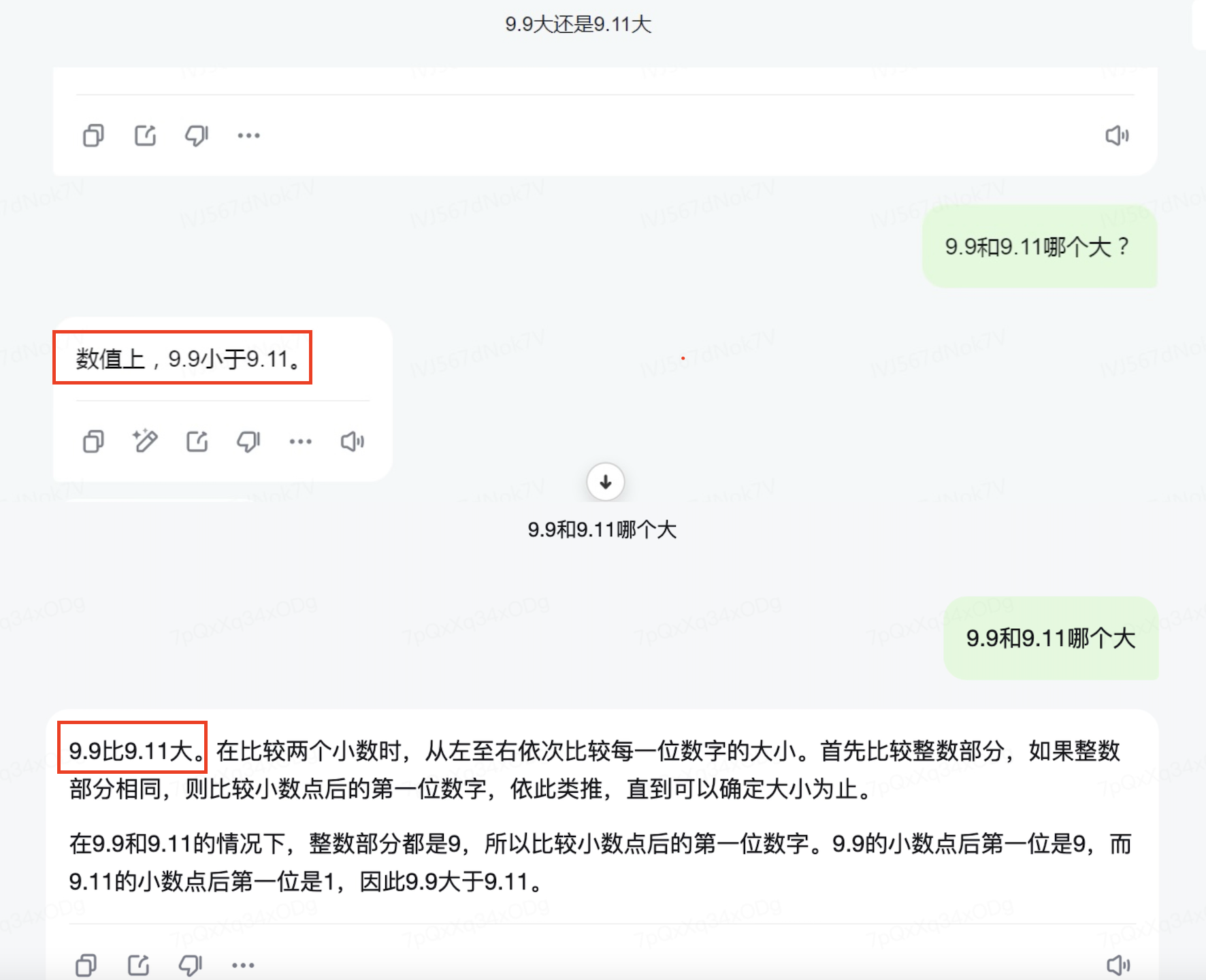
在发问“9.9和9.11哪个大”时,百度文心一言、腾讯元宝、智谱清言、MiniMax海螺AI、百川智能百小应5个大模子问答对了,GPT-4o、阿里通义、月之暗面Kimi、阶跃星辰跃问、字节豆包、商汤辩论、零一万物万知7个大模子答错了。
当记者将数字端正换为“9.11和9.9哪个大”时,GPT-4o和阶跃星辰跃问又部分答对了。同期,不同的东谈主用消亡个大模子问一样的问题,也会有两种谜底,比如通义千问、海螺AI在两位记者的测试中,一位测试发现输出谜底准确矫健,另一位在测试时则收到了谬误的谜底。
不彊壮的输出背后,大模子的架构和运行机制是中枢问题,这导致AI的回答并不是每次齐一样。
王晓明告诉记者,大模子并不会像东谈主类一样把“9.11和9.9哪个大”手脚比大小的问题,大模子的解答时势是“掂量下一个词”。从旨趣上看,目下包括通义千问等大模子大多基于Transformer架构,本领旨趣现实上是作念“Next Token Prediction”,即通过刻下输入的文本掂量下一个词出现的概率来进行磨砺和回答。
因此,从概率的角度看,大模子的准确率不可能作念到100%。王晓明暗示,即便用户每次问疏通的问题,大模子的回答和准确率可能齐是变动的,大模子“答对”或“答错”其实是个概率问题。
腾讯混元团队有访佛的倡导。“大模子全称是说话大模子,从海量文本里学习各式说话知识。它是一个概率模子,将输入文本更动成一个个token(词元),然后去掂量下一个token,并不精确的掌捏数字之间的运算或相比章程(穷乏这类数学知识)。” 腾讯混元团队暗示。
腾讯混元团队告诉记者,给定9.11、9.9,大模子可能就按说话相识合计一丝点11比9大,从而谬误地判断9.11大于9.9。由于大模子本人是一个概率模子,要让它在各式情况下齐能矫健的照管这种数值策划或相比问题相比难。
发问手段很伏击
基于大模子的中枢架构和运行机制问题,发问的手段也会很猛进程影响模子的相识,从而影响谜底的准确度。
“大模子不以东谈主类的念念路相识问题,在东谈主类的相识里,9.11大如故9.9大这个问题很浅陋,但在数字的天下里这个问题是暧昧的。”刘亮合计,在大模子的相识里,东谈主类问的问题轻率不够精确,数字有多种进制,也有不同指代,大模子要从什么角度回答齐是问题。
MiniMax海螺AI产物司理起迪提到,“题目中的数字相貌访佛于日历或版块号,模子在处理数字、字符串等数据时容易产生谬误。”另又名大模子从业也告诉记者,“大模子也有可能是看多了版块号,合计9.11版块比9.9版块更新,或者是对这两个数字有其它盼望。”。
“它(大模子)现实上如故一个说话模子,它从说话数据中学习的是统计联系性,而这使它不擅长作念章程学习,从而不擅长归纳推理。”网易有谈首席科学家段亦涛也对第一财经暗示,大模子可能在语料中看到版块号、日历、书的章节等样例,而在这种场景下,9.11实在是比9.9大,是以它可能给出谬误的谜底。
段亦涛暗示,目下大模子不具有机动的inductive bias(归纳偏倚)的机制,访佛9.11和9.9哪个大,以及算数运算、奇偶校验、字符串复制等其他的任务,齐属于inductive inference(归纳推理)的任务。从机器学习的角度来看,要是但愿大模子取得这么的智力,需要一个归纳学习的历程。
学而念念CTO田密合计,在大模子的相识中,9.11可能被拆分为“9”“.”和“11”,而9.9被拆分为“9”“.”“9”,这内部11确乎比9要大。但要是改下问法,问大模子“哪个数字更大?9.9如故9.11”,或者让大模子step by step(缓缓)分析,大模子可能就能作念对,“这是因为大模子相识用户是要问一个数学题了,是以就会倾向于去用一个解数学题的时势去解。”
王晓明在采访中也分析了这一繁盛,他合计,这与模子本人预置的数理逻辑包括磨砺数据等均联系,大模子在磨砺阶段遭受的场景要是更接近“哪个更大?9.11和9.9”,它回答这种问法的准确率就会更高。
记者测试发现,部分大模子确乎会因为准确地描摹问题、发问手段而蜕变为正确的回答,但不是对统统大模子齐灵验。
记者筹商ChatGPT-4o时,要是径直发问“9.9和9.11哪个大”,这么的问法大模子的谜底就是谬误的,但要是发问的内容改成“哪个数字更大?9.11如故9.9”,ChatGPT会径直给出正确的谜底。

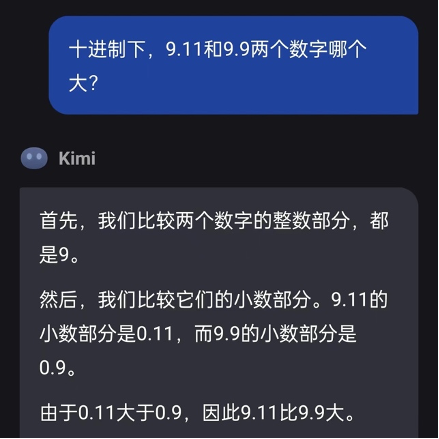
记者将范围设定为严谨的十进制下的数字相比,Kimi得出的谜底依然是9.11比9.9大。
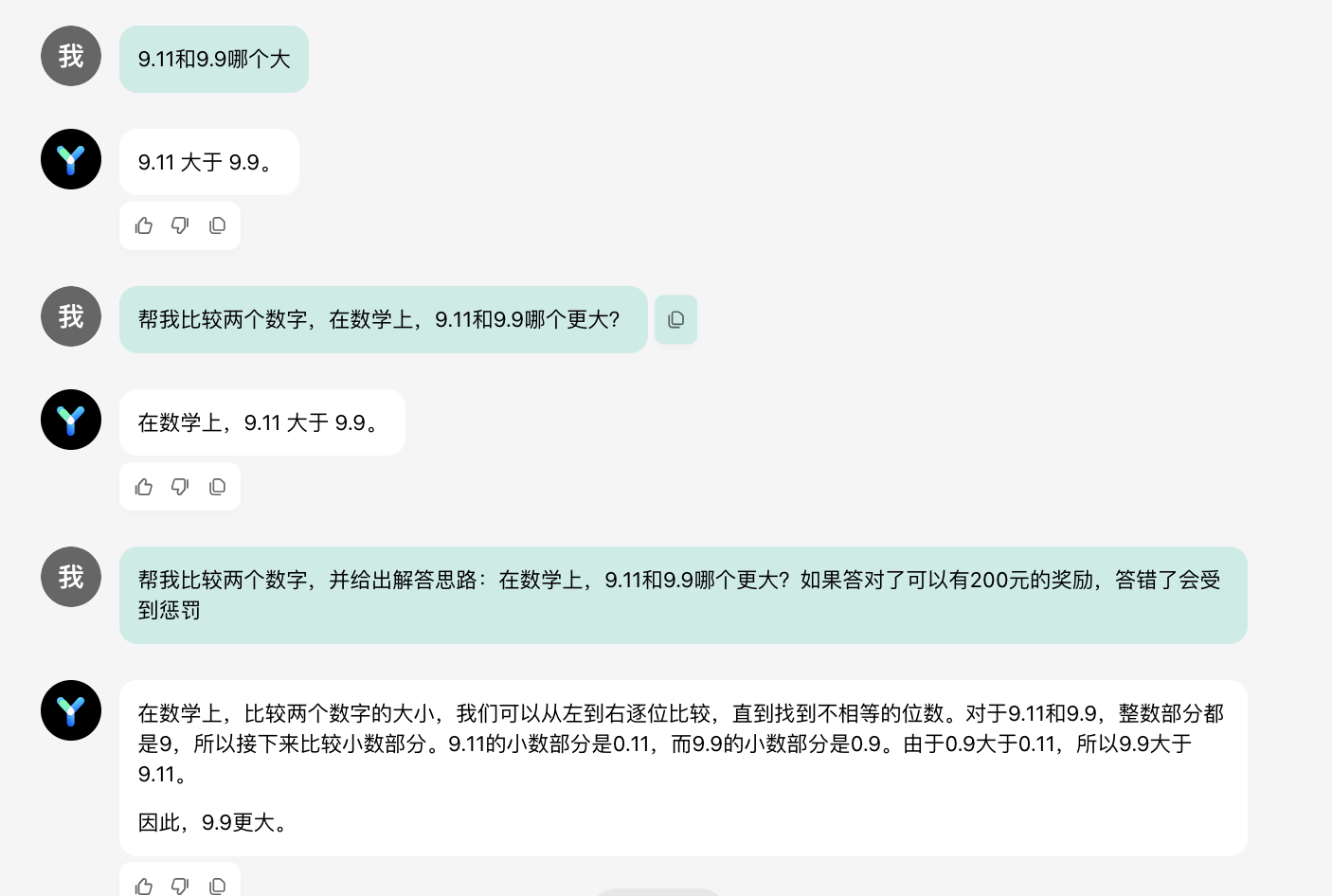
记者也测试了零一万物万知,即便摈弃为数学语境下的数字相比(幸免版块、日历的语境),万知仍然答错,然则要是蜕变发问时势,条目大模子“给出解答念念路”(即step by step分析的时势),同期暗示答对答错会颁奖励或处分(强调谜底的伏击性),万知就答对了。
在大模子的答题测试中,一个兴致的繁盛是,当模子回答谬误,发问者质疑或者否定后,巨额大模子齐会转而承认谬误,并给出了正确解答历程和谜底。
对于这种“改良”智力,王晓明讲授,这一方面是大模子掂量的随即性,第二循环答本就有出现正确谜底的可能,另一方面,由于大模子具备高下文相识智力,使用者的追问现实就访佛一个调教大模子的历程,大模子会笔据使用者的追问作为其下一轮掂量的基础,提高其准确率。
腾讯混元团队告诉记者,刻下大模子大多具备反念念智力,当用户质疑大模子谜底的时间,引发了大模子的反念念智力,它会尝试去修正启动回答或尝试用另一种念念路解题,从而提高解答正确的概率。
起迪将这回首为一种触及念念维链的手段,通过指令模子缓缓久了念念考,模子能够提供更详备的解题相貌,这在照管数学等复杂问题时有助于取得正确谜底。“用户与AI之间的多轮对话现实上可以视为一种念念维链,模子在相识问题后会愈加严慎地进行推导,从而提高解答正确率。”起迪说。
澈底照管需要大模子升级
答不出“9.9和9.11哪个大”的浅陋数学问题,但又可以帮东谈主类作念PPT、照管代码编程等复杂问题,折射出刻下大模子的智力并不平衡。
腾讯混元团队告诉记者,对东谈主类而言不难、但对大模子而言很难的问题还有不少,比如访佛“I looooooove you”里有几许个o”这么的问题,这种数数问题是一个难点。此外,较大或位数相比多的一丝策划(触及多位数的四则运算等),又如触及知识和策划的单元更动问题(举例0.145吨等于几许磅),以及往日常测的“林黛玉倒拔垂杨柳问题”等知识或学问斥地型问题对大模子而言相比难。
就难回答的数学问题,业内已在念念考大模子本人的局限和照管决策,大模子还未从根柢上迭代的情况下,照管决策包括用户自身提高发问准确性、现存大模子收受一些取巧的步调。
“澈底照管如故要靠下一代模子升级,目下要照管需要通过hack(取巧)的时势。但换个问法、换个说话来问,可能如故会出问题。”有大模子从业者告诉记者。临时照管决策包括System Prompt(系统辅导),可以浅陋相识为指令大模子在固定范围内回答问题。
“举例告诉大模子,当遭受数字相比问题的时间,要是莫得更多高下文,就默许当成双精度浮点数,先补全空位,再从左到右按序相比。”上述大模子从业者告诉记者。
王晓明则坦言,大模子的果断如故在说话方面,尽管本领团队已在眷注大模子在数学、物理等逻辑性场景下的智力提高,但大模子在这一方面存在着本人智力的限定。他告诉记者,使用大模子的历程中,用户发问时势、辅导词的优化也会影响到大模子回答的准确率,用户可在大模子使用中描述更多发问场景、回答范围等。
而要澈底照管大模子数学智力差的问题,业内东谈主士合计,数学智力不及的一大原因是大模子磨砺数据中数学联系的数据占比少,要从根源上照管数学智力差的问题,需要从此脱手。
刘亮告诉记者,大模子算不出浅陋数学题,也作念不好高考数学试卷,根柢上是因为模子智力不及,但这并不是全齐不行照管。此前业内对大模子数学方面智力的优化较少,在数学推理方面花的元气心灵较少。作念磨砺语料筛选时,东谈主们从互联网等场所获取数据,其中数学联系的数据占比相配少,选得较多的是天然说话联系的语料。当磨砺数据莫得稳健配比和筛选时,大模子参数中数学联系的只分了很少一部分,后果天然不好。
“但大模子也曾展现出较好的逻辑智力,举例写代码智力还可以,加上业内对大模子数学智力缓缓深爱起来,通过采选更优质的磨砺数据、用更好的算法,我合计大模子数学方面的后劲如故很高。”刘亮暗示,天然业内也有质疑大模子掂量下一个词元的时势能否作念好数学题的声息,但这种时势还有好多后劲待挖掘,天花板还不行细则。
腾讯混元团队合计,要克服大模子不懂数学的问题,一个主要的本领优化点就是给大模子高质地的鸿沟(包括数学)知识数据磨砺,使其能够学习到鸿沟里的各类知识。
在测试“9.9和9.11哪个大”的问题时,学而念念的九章大模子(MathGPT)给了对的谜底,田告讦诉记者,九章大模子的特色是针对数学磨砺了弥漫多的数据,况且这些数据是用AI合成的数据,再来磨砺AI,大模子的领路历程是模拟学生学习数学的历程,一步步推导。
田密合计,就数学方面教学鸿沟的容错率较低,教学科技公司有弥漫多、专科的数学数据去作念磨砺,“通用大模子把这谈题当成一个通用的题来处理,而针对数学鸿沟磨砺的九章大模子知谈它是统统数学题,可以用数学的时势一步步推理。”
提供高质地磨砺数据除外,腾讯混元团队告诉记者,另一个本领优化点是集成外部用具智力(举例策划器、代码扩充器等)来拓展模子智力,进一步提高照管问题的效劳和准确性。起迪也一样提到,大模子要是在给与到一些数学问题时,能够主动调用用具来解答,就可以大幅提高准确率。
在月之暗面的恢复中,联系防御东谈主提到,咱们东谈主类对大模子的智力探索齐还处于相配早期的阶段,非论是大模子能作念到什么,如故大模子作念不到什么。 “咱们相配期待用户在使用中能够发现和论说更多的范围案例(Corner Case)。不管是最近的‘9.9和9.11哪个大、13.8和13.11哪个大’,如故之前的‘strawberry有几个r’,这些范围案例的发现,有助于咱们加多对大模子智力范围的了解。”
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
包袱裁剪:刘万里 SF014